So, do the different linguistic family trees of Indo-European tell you different things? I think that grammar-based trees are better at telling you about the original splits between language sub-groups, whereas word-based trees can tell you about how isolated those sub-groups became.

Why are these two family trees for Indo-European so different in shape?
At the beginning of the millennium two papers were produced which both purported to show, using statistical ‘cladistic’ analysis, the structure of the Indo-European language family. The resulting family trees of the two studies were completely different.
Gray & Atkinson’s 2003 study was based largely on modern IE languages, and used the existence of related words in the lexicon of each of the languages to construct a family tree. Ringe, Warnow and Taylor’s 2002 study instead used the earliest languages that they could and, as well as the lexicon, also used grammatical (morphology) and sound change (phonology) features to help classify the results.
And the tree shapes would have, frankly, looked much the same if the linguist of the latter group, Don Ringe, hadn’t known some of the answers that he wanted beforehand. His frustration was that there were loads of shared words between languages but not that many shared morphological or phonological features. Yet his hunch was that the latter features were more important than the words.
So what Ringe’s group did was to weight morphology and phonology hugely compared to the words. This gave them answers that made sense to Don Ringe but left the group subject to some criticism for effectively biasing the data. What he was saying was, in effect, that the words were of lesser importance than the grammatical rules.
Now, what I find frustrating is not that Ringe’s group weighted the data but that they didn’t just go the whole hog and dump the lexicon altogether, just concentrating on morphology and phonology. Maybe they didn’t think that there was enough data. Either way it would have been nice to see the results of such a study.
Building trees from words, sounds and grammar
Don Ringe’s bias was to say that words are important, but not that important in constructing the history of IE languages. He attributes this in part to word borrowing between languages. Whilst Ringe’s group did their best to spot word borrowing and filter out the borrowed words, they admit that they may have failed to detect borrowing between languages.
In this they appear to disagree with Andrew Garrett, who thinks exactly the opposite. Andrew Garrett’s position is that the current phonology and grammatical rules of IE language sub-groups are late features, formed as a result of geographically adjacent IE dialects converging in their grammars and sounds. This, he argues, is the result of crises. Therefore Garrett prefers to see the words as being key to older connections, as these are less likely to be changed in his opinion.
The aim of this post (which has, once again, turned into an essay) is to try to see if it’s possible to look at family trees for either grammar, sounds or words and see how they differ and how they might be affected either through original shared connections or through geographical convergence.
Let’s study Indo-European morphology!
Now personally, I can’t do cladistic analysis, but what I can do is play with spreadsheets. What I’ve done here is to take phonological and morphological differences recognised between IE language sub-groups and analyse them in order to find if they reveal anything on their own.
To increase the size of the list I’ve added the morphology list of Gamkrelizde & Ivanov (1995), page 345 to the phonology and morphology lists of Ringe et al. (2002) (as supplemented by the updated list of Nakhleh 2007). There may be other good, equivalent lists out there, but I don’t know about them. It should be pointed out that Ringe and G&I’s lists overlap in terms of their morphological criteria, and there are a couple of cases where a morphological criterion from one list can be mapped exactly onto that from the other.
However, the morphological interpretations of Ringe and G&I are clearly not the same. Surprisingly, in many cases where the morphological criteria appear to be describing the same grammatical feature, the list of which language sub-groups share that criterion is often not even the same. In such cases I’ve allowed each criterion to be left separate as this should prevent any bias whilst also preventing any unnecessary loss of data. However, where their morphological criteria are identical I have merged them.
Furthermore, to save complications I have only used criteria which allow the comparison of whole, well established language sub-groups. I have not used criteria which only occur in one language sub-group, as these are not informative when trying to compare sub-groups for similarity. Additionally, all criteria indicate the presence, rather than the absence of a morphological or phonological feature.
This leaves me with 40 morphological and 4 phonological criteria, a total of 44 criteria. As the 4 phonological criteria are not sufficient to be analysed on their own I’ve incorporated them into the morphological analysis.

The grammatical and phonological criteria used in this analysis and which Indo-European languages they occur in (Ce = Celtic, It = Italic, To = Tocharian, An = Anatolian, Ar = Armenian, Gr = Greek, II = Indo-Iranian, Sl = Slavic, Ba = Baltic, Ge = Germanic). The fact that this looks like a question mark is pure chance.
The list to the right shows the criteria discussed. Those marked M and P are morphological and phonological features taken from Ringe et al. (2002) p113-120 and Nakhleh 2007. Those marked G* are morphological features taken from G&I p345.
Where criteria in Ringe and G&I are similar but not identically allocated to language sub-groups, the related criteria are shown in the next column. If a criterion is exclusive (i.e. it clashes with another), then the criteria which cannot occur simultaneously are listed in the ‘opposes’ column. All criteria marked by an asterisk (*) are considered polymorphic (i.e. could develop more than once) by Ringe’s team and I’ve extended these to G&I. Criterion M11(2), although omitted by Ringe’s team from their later analysis, has been left in here, but with additions to show that it may not be unique to Italic and Celtic.
The presence of a particular feature in an IE language sub-group is indicated by a 1. Where 0.5 is given this is where G&I have indicated a potential occurrence in a language sub-group by brackets or, as in the case of M11(2), Ringe’s team suspect that related features may occur in this sub-group. These 0.5s have been ignored in the analysis, although they actually make little to no difference to the analysis.
You’ll notice that the language sub-groups and criteria have not been put in alphabetical order. They are, in fact, in the order that appears to give the highest correlations between each successive family and criterion. While it looks clearer, it also gives a hint as to how the morphology and phonology of the language sub-groups might be connected.
Please note that I have not included Albanian, Phrygian, Messapic and Venetic, which are listed either by Ringe’s team or by G&I. This is because they appear to share very few features with the other sub-groups, presumably due to either heavy loss of features (in the case of Albanian) or due to lack of evidence.
The results
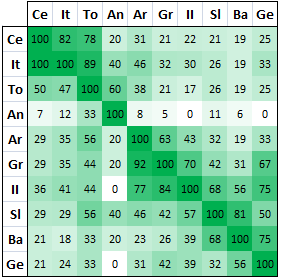
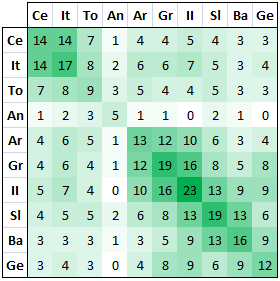 The first table indicates simply the number of criterion correspondences between different language sub-groups. It’s difficult to interpret as different language sub-groups have different numbers of potential corresponding features. The number of potential correspondences in a sub-group is indicated where both column and row have the same label: e.g. row Gr, column Gr shows the value 19, so 19 is the maximum number of correspondences that the Greek language sub-group could have with other sub-groups.
The first table indicates simply the number of criterion correspondences between different language sub-groups. It’s difficult to interpret as different language sub-groups have different numbers of potential corresponding features. The number of potential correspondences in a sub-group is indicated where both column and row have the same label: e.g. row Gr, column Gr shows the value 19, so 19 is the maximum number of correspondences that the Greek language sub-group could have with other sub-groups.
The second table shows the percentage of criterion correspondence between sub-groups. The diagonal line of 100s is simply the result of comparing a language family with itself (which gives 100%). To compare how many features Tocharian shares, say, with Italic, find the column To and compare with row It.
In this case it shows that Tocharian shares 89% of its features with Italic, but note that Italic shares only 47% of its features with Tocharian. This is firstly because Tocharian has only 9 potentially sharable grammatical features, whereas Italic has 17, meaning that Italic could never share more than 100*9/17=53% of its features with Tocharian.
Significantly, the phonological features used have little overall effect on the pattern seen and could have been removed, giving much the same result.
What comes out clearly from the data is the strong morphological relationship between Italic and Celtic as well as, to a lesser extent, of Tocharian with Italic and Celtic.
The morphological relationship of Anatolian with all other sub-groups of IE is fairly weak across the board, perhaps as a result of changes occurring either in Anatolian or in the rest of the IE sub-groups when they were still clustered as ‘late PIE’. However, although distant, Anatolian’s best apparent correlation is with Tocharian. Note however that Tocharian shares just 33% of its features with Anatolian. These are not close cousins.
Amongst the remainder, Baltic shares many features with Slavic (as is well known). Greek, Armenian and Indo-Iranian also appear to be related in some way, Greek and Armenian perhaps being more closely connected out of the three. Interestingly, Germanic shares many features with both Indo-Iranian and Baltic.
All of this evidence tends to suggest a grammatical and phonological divide between Tocharian and ‘Italo-Celtic’ on the one hand; and Armenian, Greek, Indo-Iranian, ‘Balto-Slavic’ and Germanic on the other.
However, for the remaining languages: Greek, Armenian, Indo-Iranian, Germanic, Slavic and Baltic, there appear to be chains of connection between the different sub-groups which don’t lend themselves obviously to making divisions between groups of languages.
Exclusive States
It could be argued that what we’ve got here could be purely based upon chance. Theoretically, all of these morphological and phonological features could have existed in the earliest forms of PIE and been lost randomly in individual sub-groups.
However, this is not possible in a number of cases. Some criteria, such as G13/M5, form pairs; in this case G13b/M5(1), and G13a & M5(2), indicate the type of endings found in the middle verbs of IE languages. These are exclusive states. It’s not possible to have both.
Using these criteria, it’s theoretically possible to cluster the sub-groups into groups:
Group A – Italo-Celtic, with Tocharian and Anatolian – this is based upon the presence of criteria G10a and G13b/M5(1).
Group B – Those sub-groups not in group A – this is based upon the presence of criteria G10b and related criteria M5(2) and G13a. This group (called ‘Rump IE’ by Jay Jasanoff) can perhaps be further subdivided into:
Group C – Greek, Armenian and Indo-Iranian (called the ‘Southern Dialect Group’ by Jasanoff) – this is based upon the presence of potentially polymorphic criteria G2 and G4a/M10(4). As Ringe’s team have pointed out, the possibility that these features arose more than once in the development of IE sub-groups makes this grouping weaker than it should be, but it’s the best I’ve got.
Group D – Balto-Slavic and Germanic (called the ‘Northern Dialect Group’ by Jasanoff) – this is based upon the presence of the polymorphic criteria G2c and the interrelated G4/M10a(10), M10b(13) and M9b(10), again with the same potential weaknesses as group C.
The major problem with Groups C and D is the presence in both groups of the ‘satem’ language sub-groups Baltic, Slavic and Indo-Iranian, defined by phonological criteria P2(2) and P3(2). ‘Satemization’ is not a reversible process, so if the division is correct then P2(2) and P3(2) would need to be polymorphic. One way or the other, polymorphism is a problem for subdividing group B.
Comparison with Ringe’s Analysis

The Ringe group’s best fit, family tree of Indo-European sub-groups, based on all criteria but weighted for morphology and phonology, showing the latest positions that individual grammatical or phonological criteria could have arisen.

My preferred tree for Indo-European sub-groups based purely on grammar and phonology. Note that I have chosen to see phonology as potentially able to be passed between sub-groups.
What’s shown here is the morphological tree that appears to fit the data best to me, compared to the best tree of Ringe’s team (from Nakhleh et al. 2005), produced using words as well as morphology and phonology, but heavily weighted toward morphology and phonology.
I have added morphological and phonological criteria to both trees in the position of their latest possible appearance on each tree. Criteria in black are exclusive, and are probably the most important. However, those starred are potentially polymorphic, making them less useful. Crossed out, grey criteria indicate the last possible occurrence of these criteria. Phonological criteria are red.
As Ringe’s team have pointed out, the aim of any tree is to have a continuous part of the tree occupied by one feature, except in the case of polymorphism. However, I would like to go further, and add that the aim of any tree like this is to get the latest possible appearance of the criteria as far to the right of the tree as you can.
I have chosen to downgrade the significance of phonology, accepting the argument of some linguists that satemization, as represented by P2(2) and P3(2), was a polymorphic development, happening in more than one sub-group, perhaps by convergence (e.g. the discussion over Nuristani in the Indo-Iranian family – see Hegedűs (2012)). In fact, even Ringe’s team have said ‘Because P2 and P3 are less secure than the other phonological characters and than most morphological characters, one cannot easily judge the performance of any given method by how it treats these two characters’.
Either way, this is a matter of choice. If I had taken P2(2) and P3(2) as being important I would have clustered Balto-Slavic with Indo-Iranian and made Germanic the next most closely related language, with Greek and Armenian separate.
My reason for not doing so is that it appears to push too many mutually exclusive criteria to the left of the diagram, even meaning that criteria such as M10(4) and M10(10) are required to be common at the same level, something which again only makes sense if polymorphism is used to justify their emergence repeatedly, as Ringe’s group do.
Apart from this point, the other important difference is in my grouping is of Italo-Celtic with Tocharian, which to me fits the morphology data better.
Incompatibility with words
In terms of incompatibilities (i.e. criteria or words which appear not to fit the trees), both show some incompatibilities with the filtered word list of Don Ringe’s team. For my tree, 15 words are incompatible, one twice (allx2 beard break1 breast1 drink fish1 fog2 free give1 one pour long1 straight tearx2 young2) not forgetting the additional 2 phonological incompatibilities. In the case of Ringe’s tree, 14 words are incompatible (all1 arm beard break1 breast1 float2 free head one pour straight tear thousand1 young2). Ringe clearly wins.
Words connecting incompatible sub-groups are, for both trees, largely between Germanic and either Italic or Celtic. In Ringe’s tree this is 7 out 14, whereas for mine it is 11 out of 16. As Ringe pointed out, this suggests some peculiarity of Germanic. However, the positioning of Germanic with Balto-Slavic on my tree eliminates 3 of Ringe’s incompatibles (arm float2 thousand1).
The major problem with my tree however, which lends weight to Ringe’s analysis of the position of Tocharian, is that two of my incompatibles (drink give1) are between Tocharian and Anatolian, and these could be eliminated by pairing Tocharian with Anatolian against the rest. Reordering this brings my incompatibles down to 14, of which 11 are still for Germanic with Italic or Celtic, and 2 of the remaining 3 are for 1 word.
Comparison of word and rule based trees

My modified Indo-European tree, based on the word evidence of Tocharian’s early separation before Italo-Celtic.

A Ringe/Gray&Atkinson composite Indo-European tree, based purely on the evidence of words.
Here are the diagrams of my modified morphology-based tree and Ringe’s purely word-based tree from Nakhleh et al. (which is much the same as Gray & Atkinson’s tree). In terms of word problems, this tree has just 9 words which don’t fit, compared to the 13 from my tree. However, as shown by the exclamation marks, at least three morphological criteria don’t fit, as well as three phonological criteria.
Apart from Anatolian separating first, the trees shown here are essentially different. Groups A, B, C and D do not occur in the lexical tree. Three morphologically exclusive sets, M5/G13, G10 and M8, are not obeyed by the lexical tree.
If you take the view that morphology trumps words then the tree on the left or my previous tree is more likely to be correct. If you agree with Garrett that words trump rules then (if you had to draw a tree) it would be more like that on the right. If you take the view of Ringe et al. (2002) then some kind of compromise tree is best.
So which, if any, is right?
Discussion

Is this the best tree for Indo-European languages? In making some branches interact while still mutually intelligible, this forces Anatolian, Tocharian, Armenian and Greek to the edge, whilst allowing the remaining groups to interconnect.
I think that it’s essential to bring in geography at this point and to consider which language sub-groups are likely to have been closest to which others during history. In this case, the extremes of geographical location are of Tocharian in the East (within the Tarim Basin of modern Western China) and of Celtic in the West.
Notably, these two language sub-groups appear to be quite close morphologically. This means that morphological convergence is immensely unlikely for these two language sub-groups. Conversely, Germanic, Celtic and Italic were adjacent to each other at the beginning of the Iron Age and yet Germanic is about as far, morphologically, from Celtic and Italic as it’s possible to get.
Therefore it seems to me that Andrew Garrett must be wrong, at least in his conclusions about large-scale convergent morphology. On the other hand, Garrett arguably has a better case with phonology, as it’s difficult to reconcile the morphological evidence with the phonological evidence. Furthermore, Indo-Iranian was possibly in geographical proximity to Slavic and/or Baltic during the late Bronze or Iron Age, so satemisation may have occurred during contact.
The branching that appears to be happening on the word-based tree is, on this reading, a result of long-term geographical separation. Therefore the apparent grouping of Baltic, Slavic, Germanic, Italic and Celtic is a result of these language sub-groups coming into geographical proximity within Europe whilst still mutually intelligible but after dialect variations had occurred.
On the other hand, Anatolian and Tocharian and, to a lesser extent, Greek or Armenian, appear to have become separated from the rest of IE for long enough to make them unintelligible when IE languages came into contact with them again later in history.
Was this exercise useful? Probably not. Do I feel like I’m just re-inventing Ringe’s tree? A bit. However, I do think that it’s useful to see both the Ringe group tree and the Gray & Atkinson-type tree as both potentially useful in giving clues as to the prehistoric development of IE languages.
References
Arkadiev, P. 2016 How Languages Borrow Morphology (conference powerpoint presentation).
Gamkrelizde, T.V. & Ivanov, V.V. 1984 Indo-European and the Indo-Europeans (translated by Joanna Nicholls 1995), New York, Mouton de Gruyter, pp1128.
Source of some of the grammar rules.
Garrett, A. 2006 Convergence in the Formation of Indo‑European Subgroups: Phylogeny and Chronology, In: Phylogenetic methods and the prehistory of languages, (Forster, P. & Renfrew, C. eds.) Cambridge, 139-151.
Gray,
R.D.
&
Atkinson,
Q.D. 2003. Language‑tree
divergence times
support
the
Anatolian
theory
of
Indo‑European
origin.
Nature
426,
435–439.
Hegedűs, I. 2012 The RUKI rule in Nuristani, In: The Sound of Indo-European: Phonetics, Phonemics, and Morphophonemics., Museum Tusculanum, 145-167.
Just in case you’re wondering, this is criterion P3(2), which some was not fully applied in one sub-group of Indo-Iranian.
Jasanoff, J.H. 2009 Notes on the Internal History of the PIE Optative, In: East and West: papers in Indo-European studies (K. Yoshida and B. Vine eds). Bremen: Hempen, 47—67.
As well as providing alternative names for Groups A, B and C, he argues here for the sharing of optative ending ‘*-oi’ (M6(2) in all of the ‘Rump IE’ dialects (Gk, II, Ar, Ba, Sl, Ge, including Albanian).
Nakleh, L., Warnow, T, Ringe, D. & Evans, S.N. 2005 A Comparison of Phylogenetic Reconstruction Methods on an IE Dataset, Trans. Philological Soc. 103, 171–192.
This is an extension of the work of Ringe et al. 2002, showing the different results from weighting the trees for grammar and not applying the weighting.
Nakleh, L., Warnow, T, Ringe, D. & Evans, S.N. 2004 A Comparison of Phylogenetic Reconstruction Methods on an IE Dataset (original technical report), pp23.
This is similar to the final paper, but includes un-rooted trees.
Ringe, D. & Taylor, A. 2007 (last update) – CPHL Datasets
This includes all the Ringe group datasets used in the post (with the exception of criterion M7, which they dropped). Sadly, they never appear to have made the software available.
Ringe, D., Warnow , T. & Taylor, A. 2002 Indo‑European and computational cladistics. Trans. Philological Soc. 100, 59–129.
The main paper discussed in this post.
Additional references
Josephson, F. 2013 How aberrant are divergent Indo-European subgroups? In: Approaches to Measuring Linguistic Differences (L. Borin & A. Saxena eds.) de Gruyter, 83-105.
A good discussion of some of the grammatical points at issue.
Carling, G. et al. 2014 Modelling sound change in relation to time-depth and geography: a case study on the Indo-European and Tupían language families (powerpoint presentation).
An interesting one, talking purely about phonology and attempting to make family trees based on innovations in sound features. They argue that the modern European IE subgroups (Italo-Celtic, Germanic and Balto-Slavic) are at phonological extremes from each other (bold is the most extreme), and from the rest of the Indo-European subgroups, which are all argued to be phonologically relatively conservative.
On this basis, they also group Greek with Italo-Celtic and Tocharian, and Anatolian with the rest (Albanian, Armenian, Indo-Iranian, Balto-Slavic and Germanic).
If I were to make any kind of argument for what’s going on here I would guess at two possibilities for the causes of phonological innovation:
A) it may be the result of hybrid populations changing the sounds of language. So, on this basis a relatively pure migration of a population without admixture might lead to little innovation, but a migration of a dominant minority (although still substantial) might lead to sound changes as pre-existing populations speaking different languages adopt the new language.
B) it may be the result of small, relatively isolated populations showing high mutation rates in the sound of language (a sort of ‘linguistic drift’).
In fact, the two may not be exclusive as both potentially involve relatively small population migrations.
Maybe this would be better as a post.
{ 12 comments… read them below or add one }
Dear Edward,
I would suggest to consider my results, which match modern views about the migration of the various main branches of Indo-European much better than Ringe/Anthony, let alone the Gray gang.
Best
Hans
See academia.edu; researchgate.net; Google-Scholar, and other scientific sources.
https://www.researchgate.net/publication/317231162_Steppe_Homeland_of_Indo-Europeans_Favored_by_a_Bayesian_Approach_with_Revised_Data_and_Processing_-_Updated_Bayesian_approach_with_archeological_and_linguistic_parallels
Dear Hans
Would you like to summarise those views for other readers of this blog (if there are any)?
best wishes
Ned
Good blog post; I have not seen the differences in methodology between Garrett/Chang/Grey/Atkinson and Ringe/Wardnow expressed as clearly (and so did not really understand the differences in methodology).
In your view, is there any bearing on the subject (Garrett v Ringe view on morphology/words) from –
https://www.sciencedaily.com/releases/2017/10/171002161239.htm / http://www.pnas.org/content/114/42/E8822? – which seems to suggest overt grammatical features in Austronesian show low stability over time, adoption of features when in contact with languages from other groupings, and may show anti-areal features of sharing/divergence (e.g. more change and divergence over time when subdivisions/”sister languages” are in contact rather than isolated), while core vocabulary is highly stable. (Particularly morphologically divergent languages with a stock then, would tend to be languages which adopted features from other language families during expansion, then have differences exaggerated by proximity to speakers of sister languages from the same family?). Also discussed is “poverty of choice” among grammatical features – limited number of states for each feature makes parallel evolution more probable than for words.
(Of course none of this necessarily helps us explain the particular patterns shared morphology between IE branches; certainly does not especially support Garrett’s view, which if I’m understanding it correctly is of shared areal convergence of linguistic features?)
Dear Matt
Thanks for bringing the Chang 2015 paper to my attention. I hadn’t even seen that one!
As for the other stuff I’ve never been aware of it but I’m happy to read up on it and get back to you with opinions if I can make any sense of it (by the way, linguistics is not my field… as a matter of fact I don’t have a field).
And yes, you’re right about Garrett. He believed (believes?) in the convergence of mutually intelligible dialects following Bronze Age collapse if I remember right. I struggle with the time frames of mutual intelligibility that he’s dealing in here.
best wishes – Ned
Dear Matt
I’ve only had a brief look at the Greenhill Paper so far. The obvious thing is that if their tree is correct then what they say about the greater reliability of the lexion must be true (have I got that right?). But surely this depends on the tree, and the tree largely depends on the lexicon, not the grammar (1195 cognate words vs 157 morphological and phonological rules), so that would make the result inevitable. I suspect that this can’t be a right understanding of the paper, so I’ll look again.
Have they got other evidence for the groupings given and their relative timings based on archaeology (e.g. the dates of first culture package appearance in each island)? Have they tried a purely morphology based tree?
???!!?
Well, I’ve looked again and I can’t make head nor tail of it. The statement “We compared these features with 210 items of cognate-coded basic vocabulary for the same languages” implies that they may have compared just 210 lexical features with 157 morphological/phonological rules to create a tree, which is much more reasonable, although still not 1:1. If this is the case, then which terms in the 1195 terms of the lexical database did they use? Was it based on a random choice of lexical terms or on particularly selected ones.
(I’ve just found the relevant section on page 8827, which says “The ABVD contains word lists of 210 items of basic vocabulary (e.g., simple verbs and nouns, colors, numbers, body parts, kinship terms). These items of basic vocabulary are thought to be highly stable across languages and resistant to borrowing.” So it is a biased sample but one which they believe should help in the construction of a tree. I think that the ‘thought to be… resistant to borrowing’ is interesting in this statement’.
Either way, if they could just show me satisfactorily that words trump rules in making a tree then I could stop worrying, ignore the rules, junk this post and embrace the ‘Gray tree’ (whilst perhaps ignoring its chronology). I don’t care. Just make a better argued case than this.
This all makes a lot more sense if you consider how IE branches probably spread out of the steppe. If we assume that the order of migration out of the Pontic-Caspian steppe was Anatolian > Tocharian > Italo-Celtic > Germanic > Balto-Slavic > Greek/Armenian > Indo-Iranian, you can explain a lot of the odd similarities that don’t make cladistic sense as shared retentions of archaic IE features that were lost in the core IE homeland after a given branch had split off.
IIRC the main thing that doesn’t really fit that model is the kentum/satem split, as Greek is a kentum language despite having some similarities with II over Balto-Slavic. That could have come about, however, if Greek spun off far away from the steppe before satemization occurred, while Balto-Slavic remained close enough to the steppe to share in phonological developments.
Dear F
This reply is going to sound like I’m being short with you. Apologies in advance.
What you are, in effect, saying, is that what I’ve written is wrong and that the Ringe group’s original family tree of 2002 was right. This is fine; I’m not a specialist and I’m often an idiot. However, it also shows that you haven’t read the Ringe group papers carefully.
1) Ringe’s group never argued that their tree was right, only that it was the best that they could produce to minimise inconsistencies. They are the first to admit that the evidence for much of their tree is weak, although still the best fit they could come up with.
2) More importantly, apart from where the Ringe group argues for polymorphism (which they’ve accounted for), the similarities that don’t make sense with their tree cannot be shared retentions. That is the point. This is also true of the adapted tree in this post.
As for the centum-satem subgroup division, I discussed the problems of these in the post. You either choose to make centum-satem inconsistent with the tree or to make the *bh/*m split of M9 and M10 inconsistent. There is no way to have neither as inconsistent. Ringe’s group chooses the latter, arguing for ploymorphism in M9/M10; I’m trying the former as it slightly reduces the number of word inconsistencies and makes them almost entirely of Germanic with Italic and Celtic.
Either way, with imagination it’s not that difficult to fit either (any?) tree to a steppe homeland if that’s what you want to do.
Ned
Sorry for such a late reply.
“What you are, in effect, saying, is that what I’ve written is wrong and that the Ringe group’s original family tree of 2002 was right.”
No, I actually think your trees are closer to the truth than Ringe’s – specifically, clustering Greek/Armenian and II together, and putting Balto-Slavic closer to Germanic than to the other three remainders (or at least, that’s as plausible as grouping BS with II). My main point was that your final tree makes perfect sense in the conventional steppe-IE timeline, although in hindsight it isn’t exactly clear what point I was trying to make.
Dear F
No problem about the late reply. I get quite excited when anybody talks to me at all here. I guess it’s that dopamine rush.
Sorry that I was so short with you last time. Sometimes I’m just more difficult than at other times. Yes, I absolutely agree about the steppe compatibility. My position on it is just agnostic, so I wanted to look at Ringe’s data and analysis to see if I could get more understanding. Sadly, it sort of doesn’t answer any questions, which is unsurprising, but it does at least help with fitting any future data to find a more accurate story and prevent me from having opinions without evidence.
thanks for the reply anyway.
Ned
Hi Ned! Love this post! And I thoroughly enjoy the methodology, gosh you’re good at this. Just a hammer, a few nails and a piece of wood … But it seems to me now it brings out all the salient points. Not sure yet, must study some … I’ll get back to you when I have.
PS Isn’t Tocharian a poser? Relatively young (compared to Latin, Sanskrit, and Hittite), but with such an old split. I used to attribute it to R1b clans from the steppe, only to be told that the Takla Makan mummies are R1a. Just assumed they were R1b because they look so damn Scottish! No use telling me they have nothing to do with Scots. I know! But then look at them! Scots, down to the sort of sheep that they got their tartans from. Somehow ‘something’ made it from there to here. The connection is in the beholder (me), but what’s going on ‘underground’ to produce this effect interests me. It’s a bit like with the Iron-Age sensibilities that I want to connect back to things of two millennia before, which you berated me for.
PPS I always think of this image of the river-delta, where there’s no telling where (upstream) the water that passes came from. And then you think you recognise an object floating by … The arms of the delta are not like a tree, because they may sever and reconnect. They may even backflow. Well, I’ll admit beeches do that too …
PPSS I hope I can give you more than a rant next time!
Dear Jaap
Thank you. I see no rant, just the same confusion that any right-thinking person has on trying to make any sense of this. Yes, Tocharian is a b?s*!*d. We don’t even have proof that the clansmen of the high deserts even spoke it, although it seems a reasonable guess. Surely some autosomal DNA on some of these mummies is not beyond someone’s capabilities? However, if they were to come from Europe, say, then R1a is not a super big problem as long as they are from the earlier, Corded Ware phases of the migration. Of course, they could just be Afanasievo-related.